Example 2
Easy concurrent SQL with amalegeni-go and Go
A nice application of amalegeni-go is that of easily writing and running concurrent sql code, like the following examples of sharded database queries.
When making the step from single-database to sharded-databases, it always seemed so complicated and tedious, writing pages and pages of code to express even the simplest query. The solution presented here scratches that itch: just write of few lines of sql mixed in with go-code, and you're done. Amalegeni-go is putting the 'ad-hoc' back into the 'ad-hoc queries'. Who said that coding for a sharded database should be a complex and frustrating experience?
The database setup
The setup here includes 16 shard databases plus 1 extra database, the aggregation database. The latter serves to store the intermediate results returned from the shards, that needs some further processing.
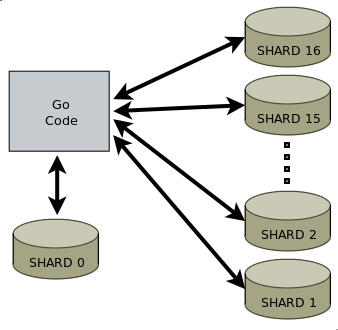
Shard Diagram
The convention used for numbering the databases is that the aggregation db is numbered 0, and the shards are numbered 1 .. 16. So in following code you'll notice that iterations don't start at 0 but at 1. For example:
for shard:=1;shard<numShards;shard++ {
..
}The data
To have a big enough dataset I loaded the nodes and tags of openstreetmap's "europe-latest.osm.bz2" file in a 16-shard setup. Each and every shard is a Postgresql instance running in its own Xen domU server. And all the virtual servers are running on 1 piece of hardware equipped with an 8-core (16-threads) CPU.
<node id="260104913" lat="50.8413737" lon="4.7905532" .. />
<node id="260104914" lat="50.8414607" lon="4.7907901" .. />
<node id="260104915" lat="50.8415126" lon="4.7931484" .. />
<node id="260104916" lat="50.8398198" lon="4.7915404" .. >
<tag k="addr:street" v="Lovenjoelsestraat"/>
<tag k="amenity" v="post_box"/>
</node>
<node id="260104917" lat="50.8397682" lon="4.791611" .. >
<tag k="addr:street" v="Lovenjoelsestraat"/>
<tag k="highway" v="bus_stop"/>
<tag k="name" v="Ezelbergstraat"/>
</node>It's quite a blob of data, the file "europe-latest.osm.bz2" is close to 17GB and after unzipping it your harddisk is suddenly 210 GB smaller.
This article is not about reading and loading the data, just assume it magically ended up in these tables in the databases:
create table t_node(
id bigint primary key,
lat real,
lon real
)
create table t_tag(
node_id bigint references t_node(id),
k varchar(127),
v varchar(1023)
)Note: only the nodes with tags are loaded, the 'standalone' nodes are ignored.
Count the records: example 1
Before we start tallying, look at the first line of following to code, to spot how amalegeni-go handles the shards identification: just put one or more dbid arguments in your function argument list.
1 2 3 4 5 6 7 8 | |
In the generated go-code you'll see that these dbid arguments are passed to the function that 'gets' the database connection. You'll also notice that these dbid parameters are of the type 'int'. It's also possible to use type 'dbidstring', for string identifiers for your shards. But because I love speed, I stick to the int type.
1 | |
Now we just need to make a loop around calling the above "Select" and Bob's your uncle. This is the way that it can be done:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Hey, why aren't we checking the errors? No worries: each and every error is logged, and reported at the end of the run. More about this later.
Compile the above (named "count.amg" in the downloadable zipfile) and run it. This is the output:
=== SHARD: 1 ===
t_node 2123557
t_tag 7072760
=== SHARD: 2 ===
t_node 2626921
t_tag 9253770
=== SHARD: 3 ===
t_node 2708526
t_tag 9232109
..
Okay, not bad, but now quit there yet, since the shards are addressed in a serial fashion, and we want to run concurrently of course!
You can read more detail on this example, or carry on with the next bit...
Count the records concurrently : example 2
The query happens in two steps:
- launch goroutines to run the sql query on each shard, put the result on the resultChannel (lines 6-11 in following source code snippet)
- pull the results from the resultChannel and aggregate (lines 16-26)
And finally print the results.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Running the serialized sql of example 1 takes about 28 seconds, while running the concurrent count of example 2 takes under 3 seconds. Pretty good improvement, I'd say!